Spaß mit Phonetik (Wintersemester 2020/21)
Spaß mit Phonetik (Wintersemester 2020/21)
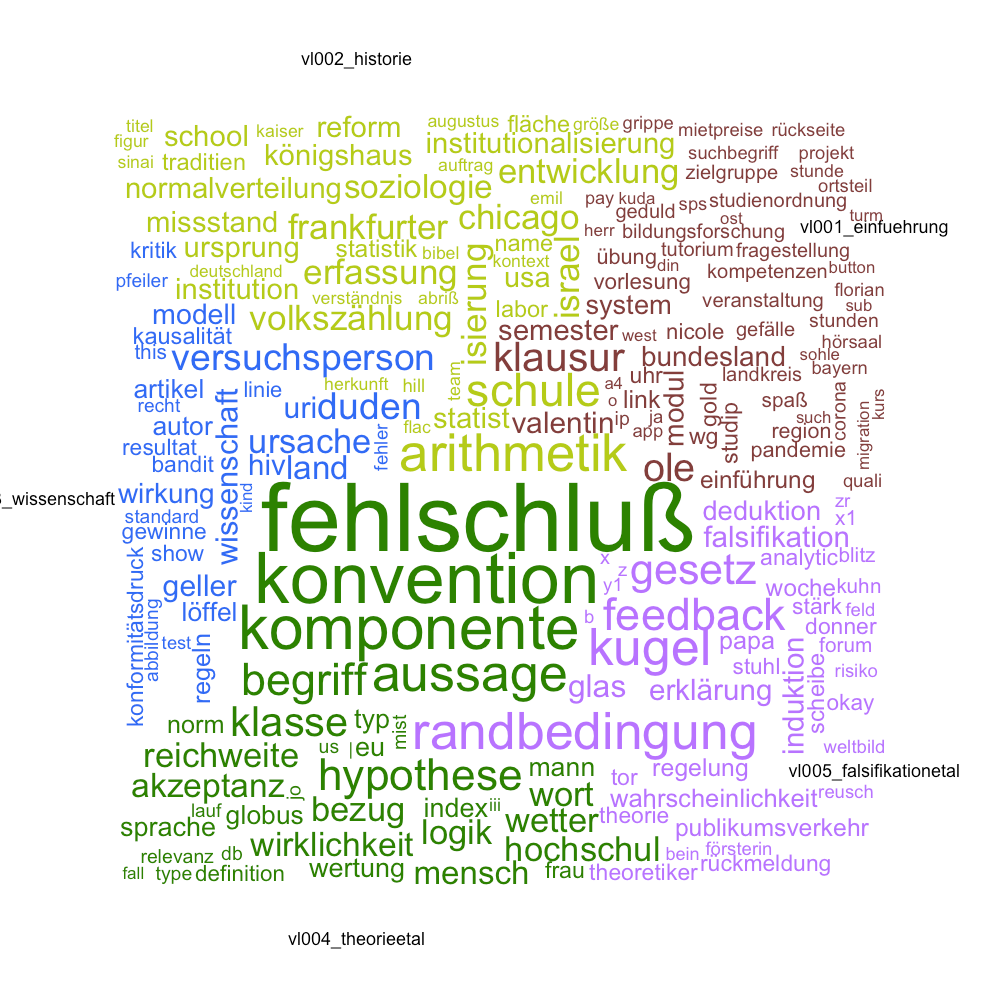 In der jeweils letzten Veranstaltung im Semester mache ich mir zumeist den Spaß (und die Mühe), die Inhalte der Veranstaltung noch einmal überblicksweise zu veranschaulichen. Allerdings nicht auf dem langweiligen Weg, sondern ich analysiere alle Folien und Skripte mit Verfahren der quantitativen Textanalyse. Das können einfache Wortwolken sein, die den Verlauf der Veranstaltung visuell skizzieren. Ein Beispiel ist die Abbildung auf der linken Seite. Der Verlauf der Vorlesung fängt bei Sitzung 1 oben rechts an und geht dann gegen den Uhrzeigersinn weiter. Die letzte hier dargestellte Sitzung ist Veranstaltung 5 unten rechts. Durch diese Darstellung kann der Inhalt der jeweiligen Veranstaltung sehr gut veranschaulicht werden.
In der jeweils letzten Veranstaltung im Semester mache ich mir zumeist den Spaß (und die Mühe), die Inhalte der Veranstaltung noch einmal überblicksweise zu veranschaulichen. Allerdings nicht auf dem langweiligen Weg, sondern ich analysiere alle Folien und Skripte mit Verfahren der quantitativen Textanalyse. Das können einfache Wortwolken sein, die den Verlauf der Veranstaltung visuell skizzieren. Ein Beispiel ist die Abbildung auf der linken Seite. Der Verlauf der Vorlesung fängt bei Sitzung 1 oben rechts an und geht dann gegen den Uhrzeigersinn weiter. Die letzte hier dargestellte Sitzung ist Veranstaltung 5 unten rechts. Durch diese Darstellung kann der Inhalt der jeweiligen Veranstaltung sehr gut veranschaulicht werden.
Im Wintersemester 2020/21 fand die Veranstaltung wegen der Corona-Pandemie digital statt, d.h. alle Vorlesungsinhalte habe ich als Podcasts vor der Veranstaltung aufgezeichnet bzw. wenn ich die Vorlesung online gestreamt habe, ebenfalls aufgezeichnet. Damit liegen nicht nur die Textdaten auf den Folien vor, sondern auch die Videoaufnahmen. Da ich bereits in einem früheren Projekt Audiodaten analysiert hatte (hier finden Sie eine Präsentation dazu), lag die Idee auf der Hand, dies auch für diese Daten einmal durchzuführen. Natürlich sind hier alle Ergebnisse nicht ganz ernst gemeint, sondern sollen die vielfältigen Möglichkeiten einmal demonstrieren.
Das Verfahren war allerdings Mitte 2020 noch sehr zeitaufwendig und kann nicht mit den jetzigen automatisierten Transkriptionsverfahren mithalten. Das Tool der Wahl war WebMAUS – mit diesem Service lassen sich die Audiodateien wieder mit dem Transkript übereinander legen. Damit wird ein Datensatz erstellt, der jedes Wort mit dem entsprechenden Audiosegment verknüpft. Aus diesem Datensatz lassen sich dann verschiedene Features berechnen und extrahieren, z.B. die Tonhöhe bzw. der Pitch. In anderen Worten: Ich kann berechnen, mit welchem Pitch ich ein Wort ausgesprochen habe. Das sieht dann für die Sitzung, in der ich das Falsifikationsprinzip erklärt habe, so aus:

Die Abbildung liest sich von links nach rechts, d.h. gegen Ende der Veranstaltung gibt es mehr Wörter, die einen höheren Pitch aufweisen als am Anfang der Veranstaltung. Soweit so gut, ich wollte allerdings noch einen Schritt weitergehen und einmal ausprobieren, ob ich klausurrelevante Wörter anders betone – hier unter der Annahme, dass sich dann den Pitch nach oben verändert. Das habe ich mit einer einfachen linearen Regression modelliert: Ich versuche den Pitch durch das jeweilige Wort zu erklären. Es sollte klar sein, dass dies eine sehr sehr simplifizierte Modellierung ist und hier für eine ernsthafte Anwendung mehr Energie (und Zeit) in die Modellierung fließen müsste.
Das Ergebnis der Modellierung wird in der unteren Abbildung dargestellt. Hier werden nur die Nomen angezeigt, für die das lineare Modell eine Signifikanz von kleiner als \(0.1\) ausgibt. Offensichtlich gibt es einige Nomen, die ich signifikant anders betont habe, z.B. die Begriffe “Intercept”, “Y1” oder auch “Ruhe”. Wenn Sie aufmerksam die Abbildung studieren, sehen Sie das Wort “Gorilla” – mit diesem Wort demonstriere ich eine der Herausforderungen von Beobachtungen. Ich habe allerdings in der Klausur nicht das Wort Gorilla genutzt und das Thema hatte (zumindest meiner Wahrnehmung nach) auch keine besondere Relevanz in der Klausur. Der Mehrwert dieser illustrativen phonetischen Analyse für die Klausur ist also eher begrenzt\(\ldots\)
