Ideologische Klassifizierung von Tweets
Analysis
DE
Lektürekurs Quantitative Sozialforschung
Im Rahmen des Lektürekurses Quantitative Sozialforschung, der in diesem Wintersemester 2023/24 stattfindet, besprechen wir im Kurs die Anwendung großer Sprachmodelle für die sozialwissenschaftliche Forschung. Der Kursplan sieht vor, dass wir im Seminar neben einer allgemeinen Einführung in die Funktionsweise solcher Modelle zahlreiche sozialwissenschaftliche Anwendungen diskutieren. Im Fokus der Diskussion stehen die Fragen,
- ob große Sprachmodelle die sozialwissenschaftliche Forschung verändern,
- wie sie die Forschung verändern und
- wie gut große Sprachmodelle bereits klassische sozialwissenschaftliche Aufgaben übernehmen können.
Darüber hinaus ist die Idee, gemeinsam ein kleineres Projekt durchzuführen und die Ergebnisse großer Sprachmodelle mit bisherigen Forschungsergebnissen zu vergleichen. Das ist auch der Fokus dieses Posts: Ich demonstriere eine kleine Anwendung, mit der das Potenzial großer Sprachmodelle deutlich wird.
Ideologische Klassifizierung
Die ideologische Klassifizierung ist vor allem für die Politikwissenschaft relevant: Die zugrundeliegende Frage ist, wo sich einzelne Akteure auf einer politischen Dimension verorten bzw. verorten lassen. Die Akteure sind üblicherweise Parteien bzw. Parteivertreter und -vertreterinnen. Typischerweise werden Parteiprogramme oder Äußerungen von Parlamentariern und Parlamentarierinnen im Bundestag oder in den sozialen Medien als Datengrundlage für die Klassifizierung herangezogen. Neben der klassischen Links-Rechts-Dimension können Akteure auch auf anderen Dimensionen klassifiziert werden, z.B. Pro- und Kontra-EU-Integration, Liberale und Konservative Wirtschaftspolitik oder Liberale und Konservative Migrationspolitik.
Es gibt zahlreiche Verfahren, mit denen Akteure bzw. deren Äußerungen klassifiziert werden können, u.a.
- Qualitative Klassifizierung
- Selbsteinschätzung über Fragebögen
- Fremdeinschätzung durch Experten und Expertinnen, z.B. Chapel Hill Expert Survey
- Quantitative Verfahren, u.a.
- Große Sprachmodelle, z.B. ChatGPT
Die meisten der hier aufgelisteten Verfahren entsprechen einem maschinellen Lernverfahren: Auf Basis bereits ideologisch klassizierter Daten werden neue und für das Modell unbekannte Daten entsprechend automatisiert klassifiziert. Bei der Anwendung solcher Verfahren dürfen drei Dinge nicht vergessen werden:
- Es werden nicht Akteure klassifiziert, sondern deren Äußerungen. Auf Basis der Äußerungen wird dann die Position der Akteure bestimmt bzw. geschätzt.
- Statistische Verfahren weisen Unsicherheiten auf, die im besten Fall angegeben werden können.
- Viele Modelle setzen Trainingsdaten voraus, d.h. die Äußerungen müssen adäquat klassifiziert sein. Wenn die Trainingsdaten fehlklassifiziert sind, ist es auch das Ergebnis der Modelle.
Anwendung
Um die Bandbreite in der Anwendung großer Sprachmodelle zu demonstrieren, haben wir im Seminar den Artikel von Ziems et al. 2023: Can Large Language Models Transform Computational Social Science? diskutiert. Hier wird demonstriert, wie mit Hilfe von ChatGPT Äußerungen ideologisch klassifiziert werden können. Das von mir angewandte Verfahren zur Klassifizierung der Tweets entspricht fast dem Verfahren von Ziems et al. – mit zwei Änderungen:
- Das technische Framework, mit dem die Klassifizierung erfolgt, ist GPT4All
- Zur Klassifizierung der Daten nutze ich ein Open Source Modell.
Replikation
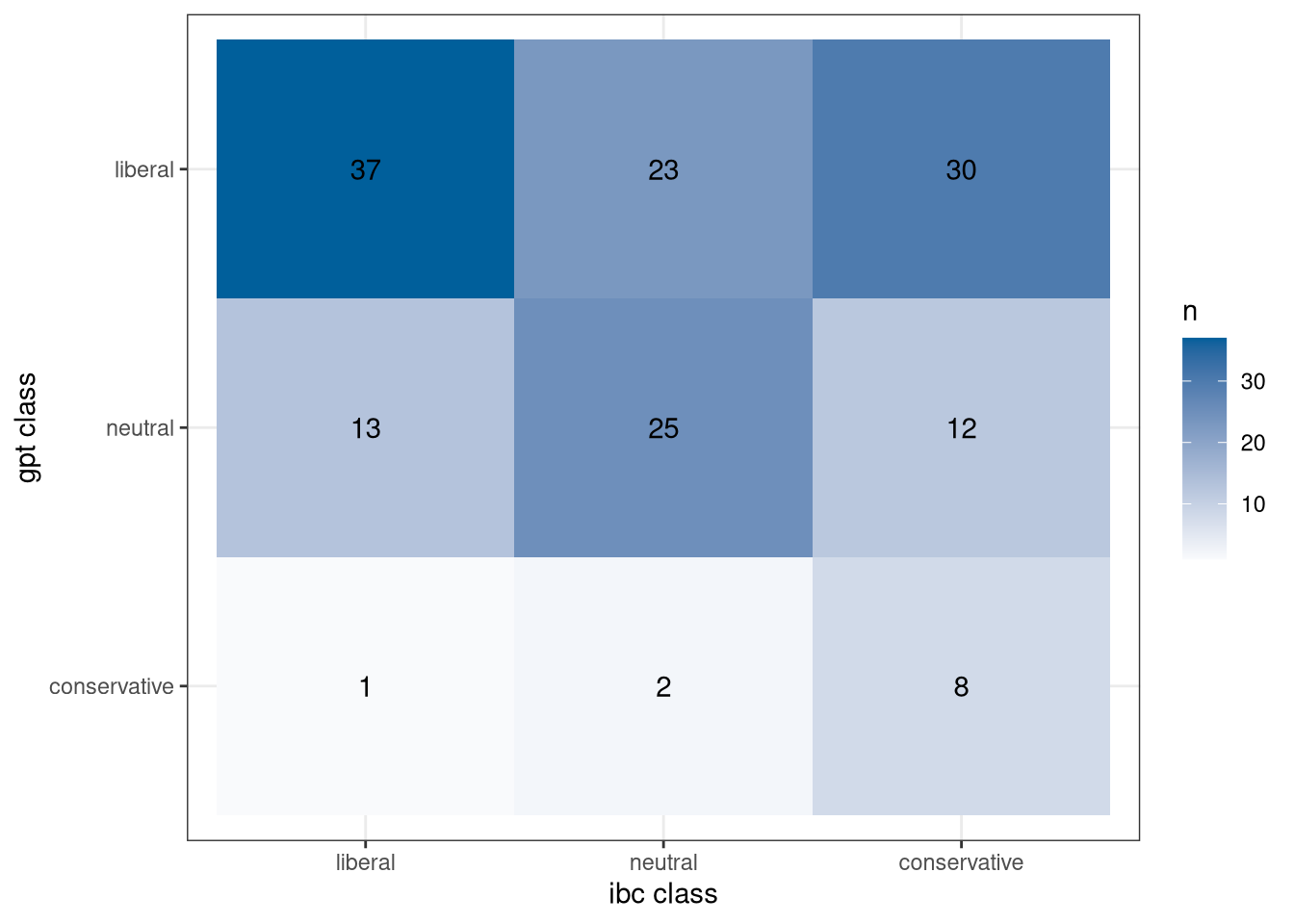
In einem ersten Schritt habe ich die Klassifizierung von Ziems et al. mit dem Beispieldatensatz des Ideological Book Corpus repliziert. Die entscheidende Frage ist, ob das Open Source Modell eine ähnlich gute Qualität wie ChatGPT ausgibt. Das Ergebnis ist vergleichsweise entäuschend: Die Abbildung zeigt deutlich, dass die von dem Modell zugeordneten Klassen (y-Achse “gpt class”) von der manuellen Annotation (x-Achse “ibc class”) abweicht. Die Erwartung sind viele übereinstimmende Klassifikationen, d.h. hohe Werte auf gleichlautenden Klassen. Dem ist aber nicht so. Das Modell macht besonders viele Fehler bei der Klassifizierung konservativer Texte: Viele konservative Texte werden vom Modell als liberal klassifiziert (siehe Zelle oben rechts). Zumindest dieses Modell ist also mit diesen Daten und diesem Befehlsprompt zu Gunsten liberaler Ideologie verzerrt. Ob das auch für Tweets zutrifft?
Tweets
Die Tweets habe ich im Rahmen des Masterseminars M.MZS.12 Multivariate Datenanalyse in 2021 erhoben. Damals haben wir die Anwendung quantitativer Textanalyseverfahren besprochen und hierzu Tweets von Bundesparlamentariern und -parlamentarierinnen gesammelt. Die Tweets sind vermutlich nicht vollständig und von einigen damals aktiven Personen konnte der Twitter-Account nicht recherchiert werden (bzw. der Account war weder auf der Bundestagsseite noch auf abgeordnetenwatch.de verzeichnet). Um die Anwendung eines großen Sprachmodells exemplarisch zu testen, habe ich für jede Partei zufällig 1000 Tweets ausgewählt und durch das Modell die politische Verortung ausgeben lassen.
In der nächsten Abbildung wird für jede Partei die Häufigkeit der ausgegebenen Klassen dargestellt: Die Anzahl konservativ klassifizierter Tweets nimmt von oben nach unten ab. Die größte Anzahl konservativer Tweets kommt von der Partei AfD, die geringste Anzahl von der Tierschutzpartei. Allerdings sieht man deutlich, dass die unteren beiden Parteien nicht dieselbe Anzahl an Tweets aufweisen.
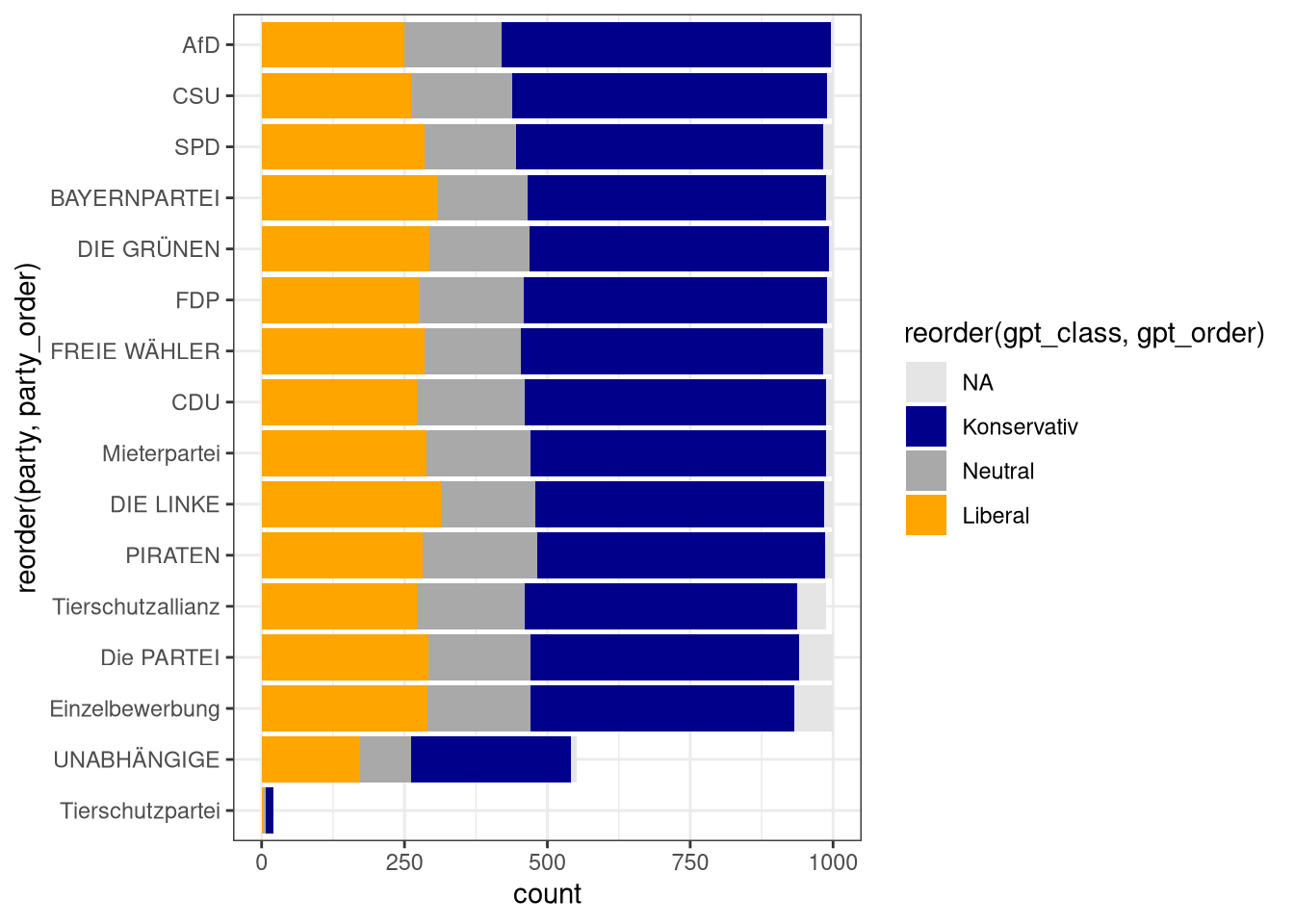
Die Anzahl der Tweets wird auch noch einmal in der nächsten Abbildung auf der rechten Seite abgebildet. Ich habe auch einmal einen sehr einfachen Score für Konservatismus berechnet, in dem die Anzahl konservativ-gelabelter Tweets durch die Anzahl liberal-gelabelter Tweets geteilt wird. Auch wenn der Score (zu?) sehr vereinfacht, entspricht die vom Modell ausgegebene Klassifizierung in der Summe ungefähr der politischen Ideologie der Parteienlandschaft in Deutschland.
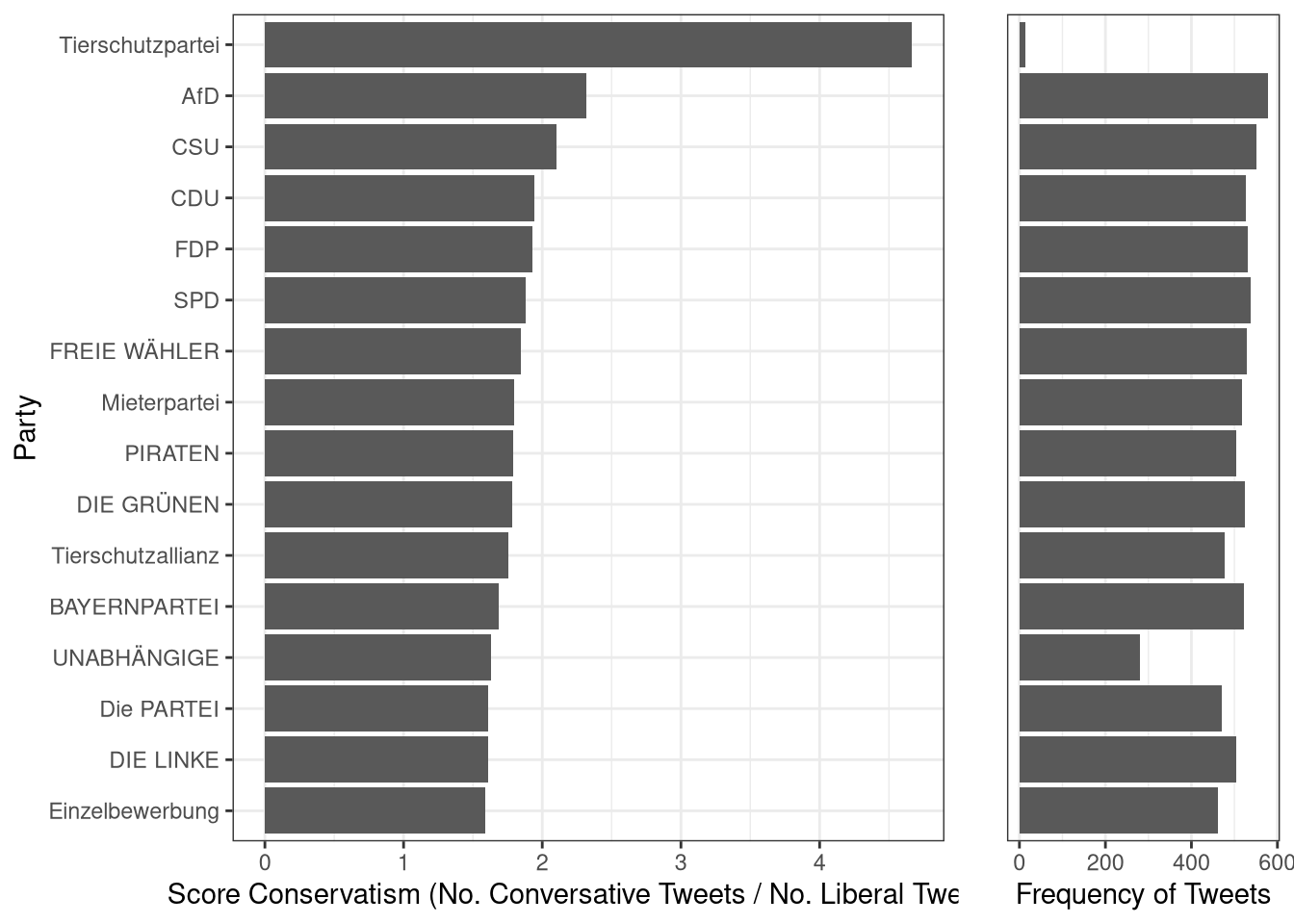
Während also die Replikation fehlschlägt, ist die Ausgabe des Modells in der Summe durchaus realistisch. Besonders bemerkenswert finde ich, dass die beispielhafte Anwendung trotz eines eher Quick’n’Dirty-Verfahrens ganz gut funktioniert. Für eine ernsthafte Anwendung müsste der Datensatz natürlich näher inspiziert werden und auch der Befehlsprompt könnte verbessert werden. Erst dann ließen sich inferenz-statitische Aussagen treffen.