ADD-update
ADD-up
Obwohl das ADD-up Projekt offiziell beendet ist und die Finanzierung ausgelaufen ist, überlege ich hin und wieder, ob die in den letzten drei Jahren vorgestellten Verfahren die Analyse und Visualisierung von Kommunikation verbessern können. Ich denke dabei vor allem an große Sprachmodelle wie z.B. ChatGPT oder Gemini. Ein Anlass, das zu testen, war die interaktive Ausstellung KI & Data Science Erleben, die Anfang November im Digital Creative Space der SUB Göttingen stattfand. Im Rahmen der Ausstellung habe ich einen Vortrag gehalten und das ADD-up Projekt vorgestellt. Einen kurzen Bericht über die Ausstellung befindet sich hier. Die Wochen vor dem Vortrag habe ich dazu genutzt, dem technischen ADD-up Framework ein Update zu verpassen. Auf dieser Blogseite berichte ich kurz über die vielfältigen Anpassungen, die ich vorgenommen habe.
ADD-update
Ich habe das ADD-up Projekt in dreifacher Hinsicht aktualisiert:
1. Einbindung Whisper (OpenAI)
In der bisherigen technischen Implementation haben wir für die Transkription gesprochener Sprache zwei Verfahren implementiert:
- Zu Testzwecken haben wir auf die Speech-to-Text Schnittstelle von Google zurückgegriffen. In dieser Schnittstelle war bereits vor drei Jahren eine automatische Erkennung der Sprecher und Sprecherinnen inkludiert, die allerdings nur so mäßig gut funktioniert hat.
- Wir haben auch eine lokale Lösung implementiert, so dass die Audiodaten nicht zu Fremdservern geschickt werden müssen. Aufbauend auf dem SEPIA-Framework mussten wir die Sprecher und Sprecherinnen allerdings manuell angeben.
Gerade bei der Transkription von gesprochener Sprache hat sich in den letzten Jahren sehr viel getan. Hier ist vor allem das Spracherkennungssystem von OpenAI, Whisper, zu nennen. Das Modell ist unter einer Open Source Lizenz frei verfügbar und kann somit auch lokal zum Einsatz kommen. Um Whisper in das technische ADD-up Framework einzubinden, habe ich auf den Whisper Playground zurückgegriffen. Der Playground kombiniert eine Webplatform mit Mikrofon-Input und der automatisierten Erkennung von Sprechern und Sprecherinnen. Für die Demonstration auf der KI-Ausstellung musste ich nur noch eine Datenbankschnittstelle hinzufügen.
2. Rückgriff auf Sprachmodell Llama2 (Meta)
Damit das ADD-up System auch in realen Diskussionen zum Einsatz kommen kann, wurde von unseren Anwendungspartnern eine lokale Lösung bevorzugt: Alle Daten, die im Rahmen der Kommunikation anfallen, sollen lokal verarbeitet werden. Und das bestrifft nicht nur die Audiodaten (für die Transkription), sondern auch die Analysen: diese müssen lokal auf dem Computer vorgenommen werden. Damit fällt zum Beispiel ChatGPT als Analyseplatform weg.
Aber auch hier hat sich in den letzten drei Jahren sehr viel getan: Im Gegensatz zu anderen Firmen verfolgt Meta eine Open Source Strategie. Die von Meta trainierten Modelle werden bereitgestellt und können somit lokal genutzt werden. Für die Einbindung in das ADD-up Framework habe ich mich für Llama2 entschieden. Da die Kommunikation auf der KI-Ausstellung auf Deutsch erfolgte, habe ich das experimentelle deutsche Modell EM_German genutzt.
Das Hauptaugenmerk des Updates lag nicht darauf, ein produktionsreifes Framework zu erstellen, sondern die vielfältigen neuen Möglichkeiten auszuprobieren und zu testen. Daher konnten auch experimentelle Modelle zum Einsatz kommen. Das betrifft gleichermaßen die Befehlsprompts, mit denen im weiteren Schritt die jeweiligen Maßzahlen “berechnet” wurden. Im Gegensatz zur bisherigen Implementation, die vor allem statistische Verfahren zur Berechnung der kommunikativen Maßzahlen heranzieht, werden jetzt Befehle formuliert und an das Modell geschickt. Zum Beispiel kann ein Befehl formuliert werden, dass das Modell die jeweiligen Argumente einer Äußerung extrahiert. Oder entscheidet, ob zwei aufeinanderfolgende Äußerungen über dieselben Themen sprechen. Gerade bei der Argumentextraktion muss berücksichtigt werden, dass sich die Definitionen, was ein Argument ist, zwischen den statistischen Verfahren und dem Sprachmodell unterscheiden können.
3. Anpassung der Visualisierungen
Die Visualsierungen basieren im Wesentlichen auf dem älteren ADD-up Framework. Allerdings haben sie einen deutlich geringeren Funktionsumfang und müssten für einen ernsthaften Betrieb in Echzeit weiter angepasst werden. Es zeigt sich auch, dass die Performanz ein Problem ist: Die Anfragen an das Sprachmodell sind vergleichsweise rechenintensiv, was dazu führt, dass auf meinem kleinen 13-Zoll Notebook die Analyse und Visualisierung dem Gespräch nicht folgen kann. Das Problem verschärft sich mit fortlaufender Dauer des Gesprächs. Während zum Beispiel erst die fünfte Äußerung analysiert wird, ist das Gespräch eigentlich schon bei der zehnten Äußerung angekommen. Mit einem leistungsfähigeren Computer sollte das Problem allerdings nicht auftreten.
Live-Demo
Auf der KI-Ausstellung habe ich die Anwendung demonstriert. Der folgende Screenshot bietet einen kleinen Einblick in die visuelle Umsetzung. Hierfür habe ich den Ankündigungstext der KI-Ausstellung vorgelesen und meine Stimme so verändert, dass zwei Sprecher erkannt wurden – hier mit “0” und “1” markiert. Die automatisierte lokale Transkription auf Basis des kleinen Whisper-Sprachmodells funktioniert ganz ordentlich – zumindest wesentlich besser als noch vor wenigen Jahren. In der Anayse zeigt sich zum Beispiel, dass die Wahrscheinlichkeit eines Arguments in den Äußerungen des lila Sprechers größer ist als in den Äußerungen des grünen Sprechers. Aus dem Screenshot geht auch hervor, über welche Themen gesprochen wurde, u.a. Algorithmen, Datenverarbeitung, Künstliche Intelligenz und Experimente.
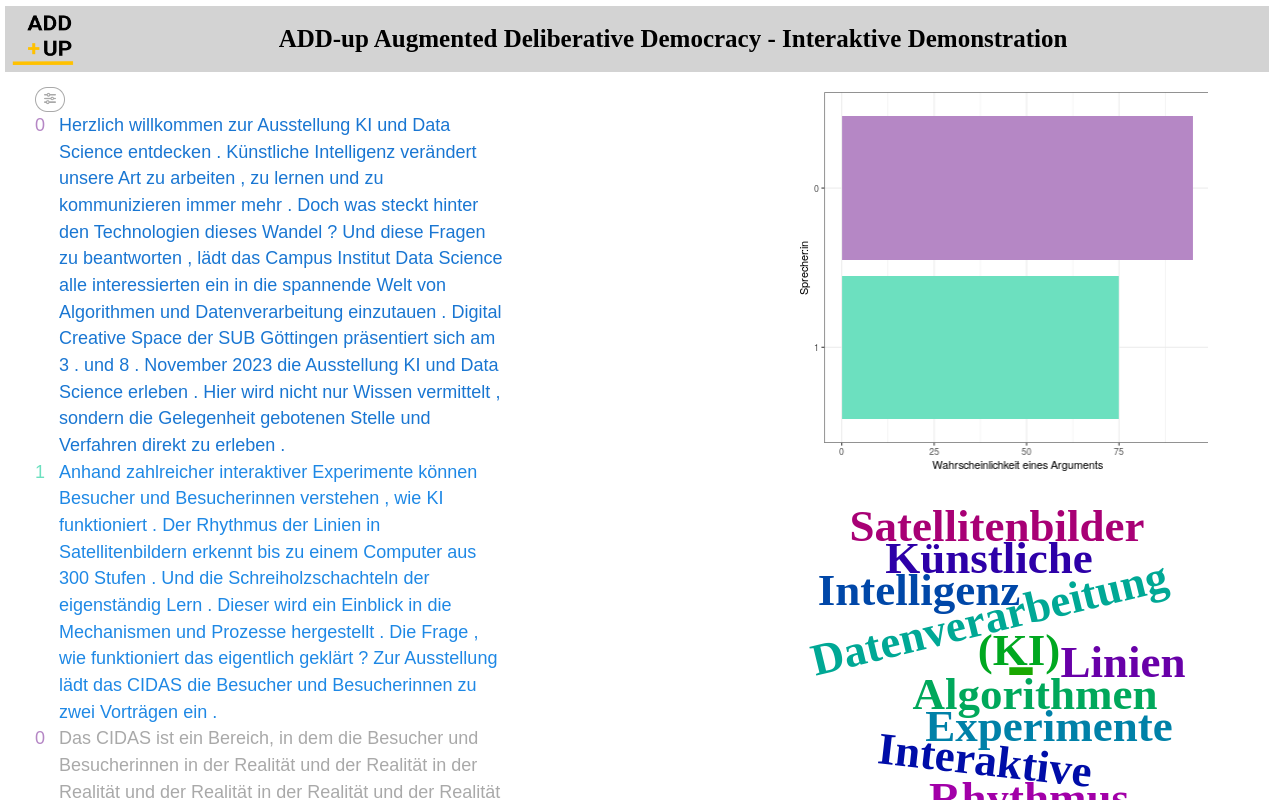
Insgesamt bin ich mit diesem kleinen technischen Update zufrieden: Die vielfältigen Möglichkeiten und Potentiale großer Sprachmodelle werden verdeutlicht und es zeigt sich auch, dass die technische Umsetzung keine allzu große Herausforderung darstellt. Das gilt natürlich nur für diese experimentelle technische Umsetzung; ein funktionsfähiger Software-Prototyp würde nur mit mehr Ressourcen umsetzbar sein.